
这里是一篇看雪OLLVM课程的学习笔记,主要记录下LLVM的基础知识,涉及到LLVM IR、Pass,为后面的编写混淆做铺垫。
1. LLVM 简单介绍
LLVM(Low Level Virtual Machine)是一个开源的编译器基础设施框架,采用模块化设计,支持多语言编译优化和跨平台代码生成。其核心架构以中间表示(IR)为基础,提供灵活的工具链用于编译器开发与优化。
LLVM 采用三段式设计:前端 -> 优化器 -> 后端
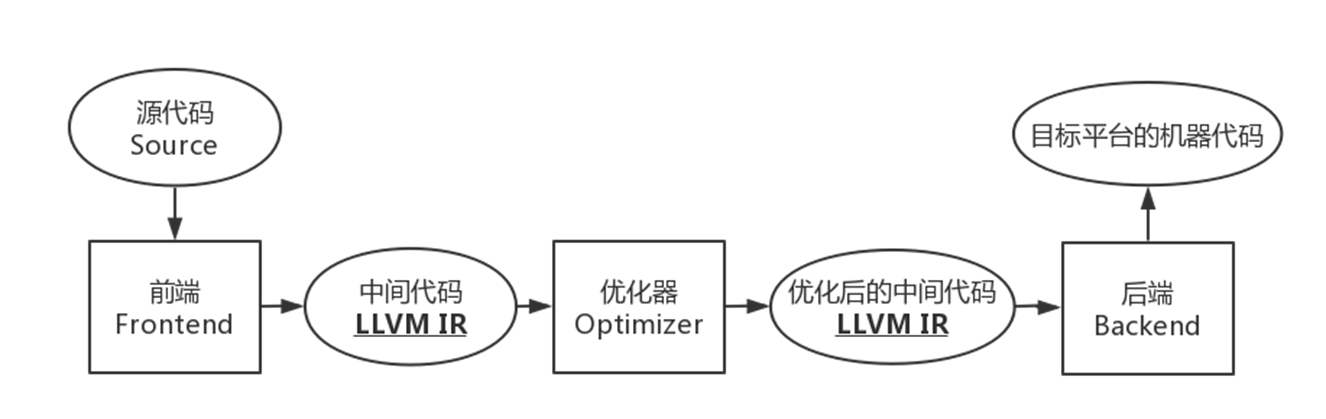
以C/C++编译流程为例简单介绍一下:
前端:采用Clang,对源代码进行:词法分析、语法分析、语义分析,得到中间代码 LLVM IR。
优化器:对中间代码 LLVM IR进行优化, 加载LLVM Pass执行自定义优化(之后编写混淆Pass就是在这一步实现,例如编写控制流混淆Pass、指令替换Pass等)。
后端:生成目标平台的机器代码!
LLVM 基本用法:
将原代码转换为LLVM IR:LLVM IR有两种文件一种
.ll结尾的,是方便阅读的文本形式;还有一种.bc结尾的,是方便机器处理的二进制格式。clang -S -emit-llvm yourfile.cpp -o yourfile.ll或clang -c -emit-llvm yourfile.cpp -o yourfile.bc
优化LLVM IR:使用
opt指令对 LLVM IR 进行优化opt -load LLVMObfuscator.so -hlw -S yourfile.ll -o yourfile_opt.ll-load 加载特定的 LLVM Pass (集合)进行优化(通常为.so文件)
-hlw 是 LLVM Pass 中自定义的参数,用来指定使用哪个 Pass 进行优化,这个参数是你自己编写的LLVM Pass中定义的。
编译LLVM IR为可执行文件:从 LLVM IR 到可执行文件中间还有一系列复杂的流程,Clang 帮助我们整 合了这个过程:
clang yourfile_opt.ll -o exeFile
2. LLVM IR
2.1 LLVM IR 介绍
LLVM IR是LLVM框架的核心中间表示形式,其本质是一种与编程语言和硬件架构无关的低级抽象语言。它承担以下核心作用:
桥梁角色:连接编译器前端(如Clang、Rustc)与后端(如x86、ARM代码生成器),实现多语言统一优化和跨平台适配。
优化载体:通过静态单赋值(SSA)形式和三地址码结构,支持常量传播、死代码消除等跨阶段优化技术。
多层次表达:提供三种形式:
文本形式(
.ll):人类可读的类汇编格式;二进制形式(
.bc):机器高效处理的序列化数据;内存表示(如
BasicBlock类):供运行时优化直接操作。
LLVM IR 的核心结构:
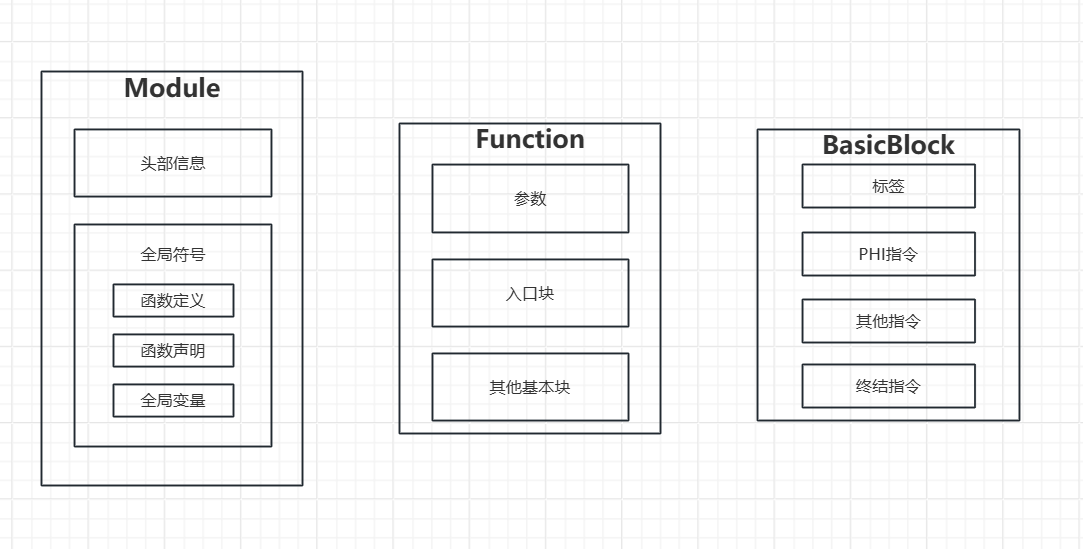
模块(Module):LLVM IR的顶层容器,对应整个源文件或编译单元,包含以下元素
全局变量:以@开头的符号(如@global_var),存储跨函数共享数据
函数定义:通过define声明的可执行单元,包含参数列表、返回类型和基本块
外部声明:declare引入的外部函数(如declare i32 @printf(i8*)),仅声明不定义实现
函数(Function):函数是IR的核心执行单元
参数列表:强类型参数(如i32 %arg),支持可变参数(...)
基本块:由标签(label:)引导的指令序列,首个块为入口块
控制流:通过br、ret等指令实现分支与返回
基本块(BasicBlock):基本块是线性指令序列
单入口单出口:仅通过首条指令进入,末尾指令(如br)决定跳转目的
SSA形式:所有变量(%tmp)为静态单赋值,避免数据流歧
指令类型:
运算指令(如add i32 %a, %b)
内存操作(load/store)
控制流指令(call、ret)
...
静态单赋值(Static Sigle Assignment, SSA):在程序中,一个变量仅能有一条赋值语句
由于LLVM IR是基于 SSA设计的,这样就会有一个问题,for(int i = 0; i<= 100; i++ ) 并不满足SSA原则
一种方式是:通过定义一个指针 int *i = (int*)malloc(4) ,之后再使用for(*i = 0; *i<= 100; (*i)++ ) ,插入内存操作指令来帮助实现for循环。
之后会配合phi 指令介绍。
2.2 LLVM IR 常用指令
1. 终结指令
一个基本块(BasicBlock)的最后一条指令
ret指令:函数返回指令,对应C/C++中的return。语法:
ret <type> <value>:返回特定类型的返回值ret void:无返回值的return指令
br指令:分支指令,对应C/C++中的if语句语法:
br i1 <cond>, label <iftrrue>, label <iffalse>:条件分支br label <dest>:无条件分支
switch指令:分支指令,对应C/C++中的switch语法:
switch <intty> <value>, label <defalutdest> [<intty> <val>, label <dest> ...]
2. 比较指令
比较指令通常和条件分支配合使用
icmp指令:整数或指针的比较指令语法:
<result> = icmp <cond> <ty> <op1>, <op2>: 比较op1与op2是否满足条件 condcond 条件可以是:eq(相等)、ne(不相等)、ugt(无符号大于)等
fcmp指令:浮点数比较指令语法:
<result> = fcmp <cond> <ty> <op1>, <op2>:比较两个浮点数是否满足条件condcond 条件可以是:oeq(ordered and equal), ueq(unorderd or equal),false(必定不成立)等
3. 二元运算
二元运算操作数类型必须严格一致,例如i32不能和i64 直接运算。SSA约束,结果必须赋值给新寄存器。
add指令:整数加法指令,如果是浮点数,用fadd语法:
<result> = add <ty> <op1>, <op2>
sub指令:整数减法指令,如果是浮点数,用fsub语法:
<result> = sub <type> <op1>, <op2>mul
mul指令:整数乘法指令,如果是浮点数,用fmull语法:
<result> = mul <type> <op1>, <op2>
udiv指令:无符号整数除法指令语法:
<result> = udiv <type> <op1>, <op2><result> = udiv exact <type> <op1>, <op2>:如果包含exact关键字,op1不是op2的倍数,就会出错
sdiv指令:有符号整数除法操作语法:
<result> = sdiv <type> <op1>, <op2><result> = sdiv exact <type> <op1>, <op2>:如果包含exact关键字,op1不是op2的倍数,就会出错
urem指令:无符号整数取余指令语法:
<result> = urem <type> <op1>, <op2>
srem指令:有符号整数取余指令语法:
<result> = srem <type> <op1>, <op2>
4. 按位二元运算
shl指令:整数左移语法:
<result> = shl <type> <op1>, <op2>
lshr指令:整数逻辑右移,右移指令位数后,在左侧补0语法:
<result> = lshr <type> <op1>, <op2>
ashr指令:整数算术右移,右移指令位数后,在左侧补0,负数,最高位置1,否则为0语法:
<result> = ashr <type> <op1>, <op2>
and指令:整数按位与语法:
<result> = and <type> <op1>, <op2>
or指令:整数按位或语法:
<result> = or <type> <op1>, <op2>
xor指令:整数按位异或语法:
<result> = xor <type> <op1>, <op2>
5. 内存访问与寻址操作
alloca指令:内存分配指令,在栈中分配一块空间并获得指针,类似于malloc指令语法:
<result> = alloca <type> [, ty <NumElemtest>] [, align <alignment>]:分配sizeof((type)*NumElements)字节的内存
store指令:内存存储指令,向指针指向的内存中存储数据语法:
store <type> <value>, <type>* <pointer>:向特定类型指针指向的内存存储相同类型的数据
load指令:内存读取指令,从指针指向的内存中读取数据语法:
<result> = load <type> <value>, <type>* <pointer>
6. 类型转换操作
trunc .. to指令:截断指令,将一种类型变量截断为另一种类型,例如将long截断为int语法:
<result> = trunc <type1> <value> to <type2>
zext .. to指令:零拓展(Zero Extend),将一种类型变量拓展为另一种类型,例如将int拓展为long,高位补0语法:
<result> = zext <type1> <value> to <type2>
sext .. to指令:符号位拓展(Sign Extend), 通过赋值符号位,将一种类型拓展为另一种类型语法:
<result> = sext <type1> <value> to <type2>
7. 其他操作
phi指令:为了解决之前的SSA引起的问题,引入了Φ函数,在LLVM IR中使用phi符号表示。phi指令的结果计算由phi指令所在基本块的前驱块确定语法:
<reslut> = phi <type1> [<val@>, <table@>], ...:如果前驱块为label0,则 result = val0
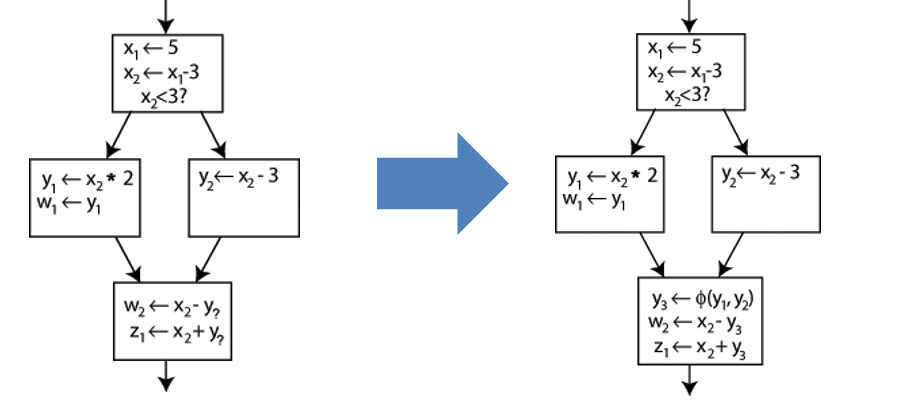
用
phi指令实现for循环的例子
Loop:
%indvar = phi i32[ 0, %LoopHeader], [%nextindvar, %Loop]
%nextindvar = add i32 %indvar, 1
br label %Loop
; 上面就是一段for(int i=0; ; i++)循环 LLVM IR phi实现
; 当 循环刚开始,从 LoopHeader 进入时,phi指令 将 indvar 赋值为 0
; 然后 将 nextindvar = indvar + 1
; 接着 继续执行循环,此时是从 Loop 进入 这个块, phi指令 将 indvar 赋值为上一轮循环的 nextindvar
; 之后继续循环...select指令:类似于C/C++中的三元运算符"... ? ... : ..."语法:
<result> = select i1 <cond>, <type> <value1>, <type> <value2>
call指令:函数调用指令,但是相较于汇编寄存器or栈传参数,这里可以直接传语法:
<result> = call <type>|<fnty> <fnptrval> (<function args>)
例如:
%retval = call i32 @test(i32 %argc):调用test函数,参数为i32类型,返回值为i32类型。
3. LLVM Pass
3.1 LLVM Pass 基础
官方文档:https://llvm.org/docs/WritingAnLLVMNewPMPass.html
LLVM Pass框架是整个LLVM提供给用户干预代码优化过程的框架,是之后编写混淆的基础。
llvm core中目录简单介绍:
llvm/include/llvm:存放LLVM提供的一些公共头文件。即开发过程中用到的头文件
llvm/lib:存放LLVM大部分源码(.cpp文件)和一些不公开的头文件
llvm/lib/Transforms:存放所有LLVM Pass的原代码,也存放一些LLVM自带的Pass
LLVM Pass支持三种编译方式:
与整个LLVM一起编译,Pass代码必须存放在llvm/lib/Transforms文件夹中(编译非常耗时!!!)
通过CMake对Pass进行单独编译(这个好)
使用命令行对Pass进行单独编译(项目越大越不好管理)
LLVM 由很多种Pass类型,例如ModulePass、FunctionPass、CallGraphPass、LoopPass等,OLLVM 主要涉及到FunctionPass。
FunctionPass以函数为单位进行处理,主要步骤如下:
类继承:
继承
FunctionPass实现
runOnFunction():处理每个函数的入口方法实现
getAnalysisUsage():声明依赖的其他分析结果
注册于加载
通过
RegisterPass模板注册Pass
char MyPass::ID = 0;
static RegisterPass<MyPass> X("mypass_cmd", "Custom Optimization");编译成动态库后由opt工具加载执行
opt -load MyPass.so -mypass_cmd -S yourfile.ll -o yourfile_opt.ll3.2 LLVM Pass 常用 API
LLVM Pass 相关 API 参考文档:https://llvm.org/doxygen/classllvm_1_1Pass.html
LLVM Pass框架中,三个最为核心的类Function、BasicBlock、Instrucetion,对应LLVM IR中的函数、基本块和指令。
一个基本类Value,所有可以被当作指令操作数的类型都是Value子类,Value有以下五种类型:常量(Constant)、参数(Argument)、指令(Instruction)、函数(Function)、基本块(BasickBlock)。
LLVM Pass中输出流:
outs():C++中couterrs():C++中ceerdbgs():C++中clog
这里只列举一些常用的API,遇到了其他需求可以查看官方文档或者搜索、AI问答解决。
1. Function
1.1 基础信息的获取
1. 函数名称与属性
getName():获取函数名称(返回StringRef)getAttributes():获取函数属性(如noinline、optnone)hasFnAttribute(StringRef):检查是否包含特定属性
2. 类型与参数
getReturnType():获取返回值类型(Type*)arg_begin()/arg_end():迭代访问函数参数(Argument对象)getArgumentList():直接获取参数列表(Legacy API)
1.2 代码结构遍历
1. 基本块操作
begin()/end():迭代函数中的基本块(BasicBlock)getEntryBlock():获取入口基本块size():统计基本块数量
2. 指令级访问
getInstructions():返回所有指令的迭代器hasAddressTaken():检查函数地址是否被引用(如函数指针)
1.3 修改与转换
1. 函数体操作
eraseFromParent():从模块中删除函数deleteBody():清空函数内容(保留声明)addAttribute()/removeAttribute():动态修改函数属性
2. 参数操作
addParamAttr():为参数添加属性(如readonly)removeParamAttr():移除参数属性
2. BasicBlock
2.1 基础信息获取
1. 名称与标识
getName():获取基本块名称(返回StringRef)hasName():检查是否已命名
2. 上下文与父对象
getContext():获取关联的LLVMContextgetParent():获取所属的父函数(Function*)
2.2 控制流操作
1. 前驱与后继
getSinglePredecessor():获取唯一前驱块(无分支时)getUniquePredecessor():同前驱(兼容旧版API)getSingleSuccessor():获取唯一后继块
2. 分支处理
splitBasicBlock():在指定指令处拆分基本块replaceSuccessorsPhiUsesWith():替换Phi节点的后继引用
2.3 指令级别操作
1. 指令遍历
begin()/end():迭代基本块中的指令(Instruction对象)getTerminator():获取终结指令(如BranchInst、ReturnInst)size():统计指令数量
2. 指令修改
eraseFromParent():删除基本块及其内容moveBefore()/moveAfter():调整基本块位置
3. Instruction
3.1 基础信息获取
1. 类型检查与转化
isa<T>():动态类型检查(如isa<BranchInst>(I))dyn_cast<T>():安全类型转换(失败返回nullptr)getType():获取指令返回值的LLVM类型
2. 上下文与位置
getContext():关联的LLVMContext对象getParent():所属基本块(BasicBlock*)getNextNode()/getPrevNode():相邻指令导航
3.2 操作数处理
1. 操作数访问
getOperand(unsigned i):获取第i个操作数(Value*)getNumOperands():操作数总数setOperand(unsigned i, Value*):修改操作数
2. Use-Def链分析
users():迭代所有使用该指令结果的指令operands():迭代指令使用的所有操作数(Use-Def链)
3.3 特殊指令处理
1. 终结指令
isTerminator():判断是否为基本块终结指令(如br、ret)getSuccessor(unsigned i):获取分支目标块(仅分支指令有效)
2. Phi节点
getNumIncomingValues():获取Phi节点入口值数量getIncomingValue(unsigned i):获取特定前驱对应的
3. 内存操作
mayReadFromMemory()/mayWriteToMemory():内存访问检测getPointerOperand():获取内存操作地址(如load/store)
3.4 修改与替换
1. 指令替换
replaceAllUsesWith(Value*):将该指令结果替换为新值eraseFromParent():从基本块中删除指令
2. 元数据操作
hasMetadata():检查是否附加元数据getMetadata(StringRef):获取指定键的元数据


